- Published on
计算机的历史
- Authors
-
-

- Name
- jamesitachi
-
Table of Contents
 馬克一號(Mark I)是美國第一部大尺度自動數位電腦
馬克一號(Mark I)是美國第一部大尺度自動數位電腦
Harvard mark I
馬克一號(Mark I)是美國第一部大尺度自動數位電腦,被認為是第一部萬用型計算機。它的生产和设计者给它起的名字是全自動化循序控制計算機(Automatic Sequence Controlled Calculator,缩写为ASCC),马克一号是它的用户哈佛大學给它起的名字。這部機電式ASCC是由IBM的霍華德·艾肯所設計的,在1944年8月7日搬到哈佛大學。馬克一號的特點為全自動運算。一旦開始運算便無須人為介入。馬克一號是第一部被實作出來的全自動電腦,同時與當年的其他電子式電腦相比它非常可靠。大家認為「這是現代電腦時代的開端」以及「真正的電腦時代的曙光」。

继电器
继电器(Relay),也称电驿,是一种电子控制器件,它具有控制系统(又称输入回路)和被控制系统(又称输出回路),通常应用于自动控制电路中,它实际上是用较小的电流去控制较大电流的一种“自动开关 ”。故在电路中起着自动调节、安全保护、转换电路等作用。
机械式继电器通过控制线路通电 导致线圈产生磁场可以将金属臂下拉闭合 从而可以控制了电路的导通,由于继电器的电臂有质量,并且金属会随着时间的磨损导致,继电器会损坏.在mark2号里面 发热的机箱会吸引了虫子 导致电路无法正常运作. 记录员就将bug(虫子/飞蛾)称之为故障
Diode 二极管
一个热离子二极管就是一个真空管(也称“电子管”),由一个包含着两个电极的密封真空玻璃壳组成:由灯丝加热的阴极,和一个阳极。早期产品的外观和现在的白炽灯泡相当类似。在操作中,一个单独的电流通过由镍铬合金制成的高电阻灯丝(加热器),将阴极加热到红热状态(800-1000℃)后可导致它释放电子到真空。这一过程即热发射。阴极通常涂有碱土金属氧化物,如钡或锶的氧化物。因为它们具有较低的功函数,可使发射的电子数量增加。有些真空管则直接加热钨丝,钨丝则既作为加热器也是阴极本身。交流电会在负极及与其同心的阳极板之间整流,当板子带正电时,静电会从负极处吸引电子。所以电子即从阴极连通到阳极成为了电流。然而当极性反转阳极板带有负电时,阳极板不会发射电子,而阴极也并不会吸引电子,因而没有电流会产生。如此则保证了电流的单向流通,即从阴极流向阳极板。在汞弧阀(具有冷阴极的汞蒸气离子阀)中,一种难熔的导电阳极与一池作为阴极的液态汞之间会形成电弧,电压单位可达数百千瓦,这对高压直流输电的发展起到了促进作用。一些小型的热离子整流器有时候也用汞蒸气填充,以减少他们的正向压降并增加这种热离子强真空器件的电流额定值。整个真空管时代,这种二极管应用于模拟信号,并在消费电子产品(如收音机、电视机、音响系统)的直流供电设备中当做整流器。20世纪40年代,在那些供电设备内的真空管开始被硒整流器所替代,然后在1960年代又被半导体二极管替代。如今,二极管仍然在一些高功率应用场合中使用,由于能够承受瞬变和较好的鲁棒性,使得他们比半导体器件的优势能够显现出来。尤其是音频处理上,真空管基本不存在瞬态互调失真、开关失真及交越失真等影响音质的问题。因此近年来,在音响发烧友和录音棚所用的音频设备中,应用真空二极管的老式音频设备有回潮的迹象,如家用音响系统甚至是吉他效果器。
通过真空,加热金属释放出电子使得电路导通,单向流通特性.
Triode vacuum tubes 三级真空管
三极管(英语:Triode)是一个有放大器功能的真空管,在真空的玻璃外壳内有三个电极:包括一个加热的灯丝(或称阴极)、控制栅格(英语:control grid)及金属平板(阳极) 。三极管是由李·德富雷斯特在1906年发明,是第一个电子放大器。也是其他类型真空管如四极管、五极管的祖先。它的发明开创了电子时代,使无线电放大和长途电话成为可能。李·德富雷斯特因为发明三极管,被誉为是电子学之父。现在的三极管只有一厘米左右的长度
通过控制正电压能导通,负电压会阻挡 从而让电路拥有了开关特性,这将是对上文提到的,继电器一个巨大的变革.因为其内部是真空的,没有移动所以使用时间很长,并且在同一时间内 可以做更多次的开合.
晶体管
电晶体由半导体材料组成,至少有三个对外端点(称为极),(C)集极、(E)射极、(B)基极,其中(B)基极是控制极,另外两个端点之间的伏安特性关系是受到控制极的非线性电阻关系。晶体管基于输入的电流或电压,改变输出端的阻抗,从而控制通过输出端的电流,因此晶体管可以作为电流开关,而因为晶体管输出信号的功率可以大于输入信号的功率,因此晶体管可以作为电子放大器。
伟大的发明 IEEE 里程碑式创造. 稳定便宜可靠快速开关,放大,稳流.
为什么是二进制
二进制 0 或者 1 代表真实世界中的开关真假. 计算机之所采用二进制的原因 一个是上面提到的晶体管会有两种形式的存在,并且当时的数学科上有一个专门处理yes/no的学科,叫做布尔代数.
与或非
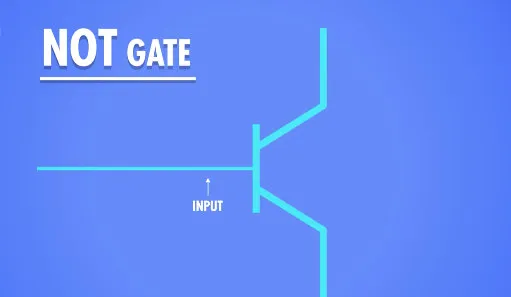
- 非:取反, 单个输入 单个输出 通过Not门把电子控制,就可以将真值表用电路来表示了
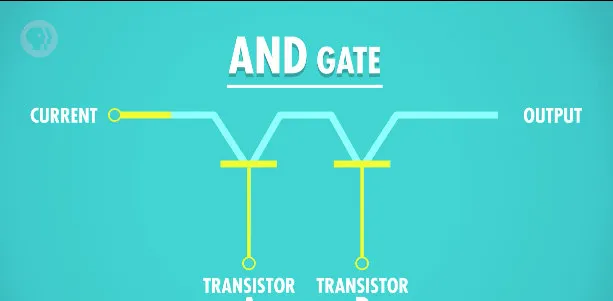
- 与: 两个晶体管来控制
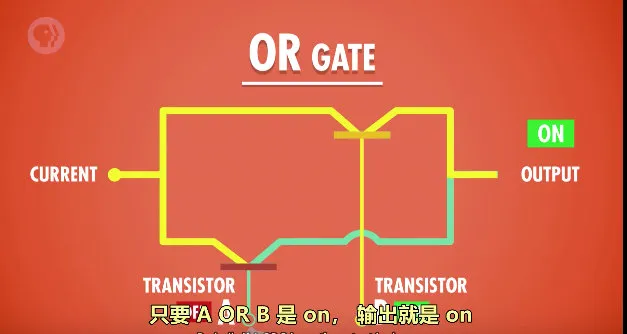
- 或: 两个晶体管来控制
xor 异或
逻辑异或 在数字逻辑中,逻辑算符互斥或闸(exclusive or)是对两个运算元的一种逻辑分析类型。与一般的逻辑或不同,当两两数值相同为否,而数值不同时为真。
二进制(知识点)
- 基础的二进制
- 8位 称之为一个byte是ibm创建的词汇 2的8次方 256最大值
American Standard Code for Information Interchange
简称ASCII:8位
| 二进制 | 十进制 | 十六进制 | 十六进制 |
|---|---|---|---|
| 0110 | 0110 | 102 | 66 |
unicode
-
非 ASCII 编码 英语用128个符号编码就够了,但是用来表示其他语言,128个符号是不够的。比如,在法语中,字母上方有注音符号,它就无法用 ASCII 码表示。于是,一些欧洲国家就决定,利用字节中闲置的最高位编入新的符号。比如,法语中的é的编码为130(二进制10000010)。这样一来,这些欧洲国家使用的编码体系,可以表示最多256个符号。但是,这里又出现了新的问题。不同的国家有不同的字母,因此,哪怕它们都使用256个符号的编码方式,代表的字母却不一样。比如,130在法语编码中代表了é,在希伯来语编码中却代表了字母Gimel (ג),在俄语编码中又会代表另一个符号。但是不管怎样,所有这些编码方式中,0–127表示的符号是一样的,不一样的只是128–255的这一段。至于亚洲国家的文字,使用的符号就更多了,汉字就多达10万左右。一个字节只能表示256种符号,肯定是不够的,就必须使用多个字节表达一个符号。比如,简体中文常见的编码方式是 GB2312,使用两个字节表示一个汉字,所以理论上最多可以表示 256 x 256 = 65536 个符号。 中文编码的问题需要专文讨论,这篇笔记不涉及。这里只指出,虽然都是用多个字节表示一个符号,但是GB类的汉字编码与后文的 Unicode 和 UTF-8 是毫无关系的。
-
Unicode 正如上一节所说,世界上存在着多种编码方式,同一个二进制数字可以被解释成不同的符号。因此,要想打开一个文本文件,就必须知道它的编码方式,否则用错误的编码方式解读,就会出现乱码。为什么电子邮件常常出现乱码?就是因为发信人和收信人使用的编码方式不一样。可以想象,如果有一种编码,将世界上所有的符号都纳入其中。每一个符号都给予一个独一无二的编码,那么乱码问题就会消失。这就是 Unicode,就像它的名字都表示的,这是一种所有符号的编码。Unicode 当然是一个很大的集合,现在的规模可以容纳100多万个符号。每个符号的编码都不一样,比如,U+0639表示阿拉伯字母Ain,U+0041表示英语的大写字母A,U+4E25表示汉字严。具体的符号对应表,可以查询unicode.org,或者专门的汉字对应表。
-
Unicode 的问题 需要注意的是,Unicode 只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。比如,汉字严的 Unicode 是十六进制数4E25,转换成二进制数足足有15位(100111000100101),也就是说,这个符号的表示至少需要2个字节。表示其他更大的符号,可能需要3个字节或者4个字节,甚至更多。这里就有两个严重的问题,第一个问题是,如何才能区别 Unicode 和 ASCII ?计算机怎么知道三个字节表示一个符号,而不是分别表示三个符号呢?第二个问题是,我们已经知道,英文字母只用一个字节表示就够了,如果 Unicode 统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,这对于存储来说是极大的浪费,文本文件的大小会因此大出二三倍,这是无法接受的。它们造成的结果是:1)出现了 Unicode 的多种存储方式,也就是说有许多种不同的二进制格式,可以用来表示 Unicode。2)Unicode 在很长一段时间内无法推广,直到互联网的出现。
-
UTF-8 互联网的普及,强烈要求出现一种统一的编码方式。UTF-8 就是在互联网上使用最广的一种 Unicode 的实现方式。其他实现方式还包括 UTF-16(字符用两个字节或四个字节表示)和 UTF-32(字符用四个字节表示),不过在互联网上基本不用。重复一遍,这里的关系是,UTF-8 是 Unicode 的实现方式之一。UTF-8 最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。UTF-8 的编码规则很简单,只有二条:1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。2)对于n字节的符号(n > 1),第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。